
Managing big data creates several challenges for data infrastructure teams:
- Managing “bursty” and unpredictable workloads
- Coordinating ad hoc and batch workloads
- Storing rapidly growing data stores that require the capability to scale quickly
- Integrating data generated at the edge
- Managing storage and compute costs
While an on-premises deployment has been the traditional method for a number of years now, many data teams are turning to a cloud solution to better address the challenges listed above by capitalizing on the benefits of the cloud’s architecture.

Cloud Architecture
Separation of Compute and Storage
Unlike an on-premises solution, which combines compute and storage in HDFS, the cloud separates compute and storage. This allows for the expansion of compute and storage separately. Given that storage is cheap and compute is expensive, this allows businesses to use compute selectively. Rather than provisioning storage and compute to peak capacity, resources can be scaled as needed. Learn More
Separation of Logical and Physical
Cloud architecture also creates a separation of the logical and physical, allowing data teams to provision workloads without using physical resources at all times. For example, one logical cluster can be configured for Spark and another for Hive workloads, and the physical cluster would be provisioned only when there is a workload.
Tiered Storage
The cloud offers greater flexibility via tiered storage. Data teams can select and adjust how data is stored depending on how accessible the data needs to be. Amazon Glacier, for example, is a low-cost storage service built for long-term storage of data that is accessed infrequently.
Service Orientation
In the cloud data, teams manage APIs rather than hardware, allowing teams to focus more on applications that impact the bottom line. Service orientation is also a low latency way to provision capacity.
Pooled Resources
The pooled resources of a cloud environment allow for practically unlimited access to resources enabling greater elasticity and multitenancy. In the cloud, workloads can expand and be shifted between different nodes and engines depending on the user’s need.
Connectivity
Since the cloud is not limited by hardware capacity, it offers greater connectivity between data sources and creates fatter data pipelines. This reduces the complexity of managing data workloads and reduces latency issues.
Geography
Since major cloud services are distributed around the world, businesses have greater flexibility over where data is stored. This provides more options for businesses collecting data in countries with legal restrictions or needing to ingest data from 3rd parties. The geographic distribution also supports hub and spoke collection, as the cloud store acts as a centralized hub that can be accessed by offices scattered throughout the world.
Benefits
The cloud’s architecture leads to six main benefits of using the cloud for big data workloads:
1. Adaptability
Cloud infrastructure can adapt seamlessly to changing workloads and business use cases. The elasticity of the cloud allows data teams to focus more on managing data and less time managing the data platform. Qubole Data Service provides additional elasticity by offering complete cluster lifecycle management. Clusters scale up and down automatically as needed to match query workload.
The cloud also allows you to select the instance type that is best suited for a given workload and gives you access to an assortment of different engines — Hive, Pig, Presto, and more — all depending on the use case.

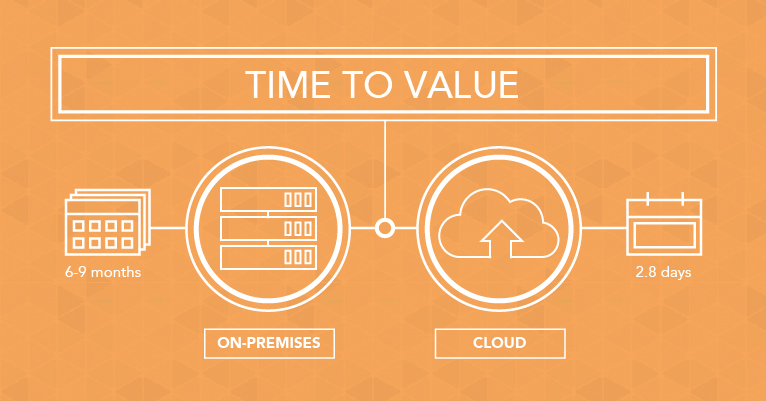
 2. Agility
2. Agility
The cloud also creates greater agility. While on-premises solutions frequently require 6 to 9 months to implement, Qubole users can begin querying their data in an average of 2.8 days. With such a low startup time, business teams are able to allocate time and resources to building applications, running queries, and extracting actual business value.
The cloud also allows teams to iteratively determine the best performance and cost and adjust it as needs change. By using the cloud, teams can adjust and optimize the configuration such as the machine type or cluster size. On-premises solutions don’t give teams this option, meaning they’re stuck with what they bought and deployed.
 3. Geographic Reach
3. Geographic Reach
As mentioned earlier, the cloud allows organizations a choice in where they can store their data. This decision can be based on factors such as overall convenience, where the data originates from, and any legal issues with the data being used
4. Lower Overall Cost
Cloud solutions offer a lower overall cost. For peak capacity to handle bursty workloads, the cloud is able to scale as needed, allowing businesses to only pay for compute space when it is needed. This takes advantage of the elasticity of the cloud, meaning you only have to pay for what you’re actually using.
Organizations running on AWS can also save a lot of money by incorporating Qubole’s automated spot instances. Qubole allows you to set a policy for each workload and then automatically bids for spot instances based on your policy. Qubole customers run nearly half their workloads using spot instances, which are 80% lower in cost. Learn More
Qubole Data Service further reduces compute costs via cloud storage I/O optimizations and faster query times.
5. Greater Fault tolerance, resilience, and disaster recovery
The cloud is more fault-tolerant and resilient than on-premises solutions. It allows enterprises to recover more quickly in the event of a disaster. If there’s a node failure or issue with a cluster, teams can seamlessly provision a new node or spin up a cluster in an alternate location. By automating this process, data teams spend less time on maintenance and can focus more on business needs.
6. Up-to-Date Security
It’s a commonly held myth that the cloud is less secure than an on-premises solution. However, the cloud is often the more secure option. Cloud providers typically dedicate much more time and resources to security and are able to adopt best practices faster.
This is the beginning of a series exploring the benefits of cloud architecture. Come back or subscribe to blog updates for more in-depth information on spot instances, the separation of compute and storage, and the economics of provisioning to the peak.



