Open source projects are forked for many reasons such as:
- Communities that hope to take the project in a different direction. For example MariaDB
- Large companies wherein the engineering team wants to assert control over patches and specific features in their internal installation.
- Companies that provide commercial distributions or services based on open source projects.
A major goal and challenge for engineering teams with the latter two use cases are to regularly pick up features and bug fixes in the open-source project and build on the efforts of the open-source community.
Qubole has forked projects that are part of the Apache Hadoop ecosystem such as Apache Spark, Apache Hive, Apache Airflow, and Presto to build Qubole Data Service (QDS). The Qubole Engineering teams have made substantial changes to these projects to make them run better on the cloud. For example, Qubole Hive, Qubole Spark, and Qubole Presto contain changes to improve INSERT queries on AWS S3 and Azure Cloud Storage. Qubole Presto contains features to work better with AWS spot nodes.
At the same time, customers expect the latest open source features to be available on the platform. In this blog post, we describe the software processes the Qubole engineering teams have adopted to provide the latest open source big data technologies containing substantial closed source changes in a reliable and agile manner.
We’re not talking about GitHub-style forks, which are actually short-lived branches that get either pulled back upstream or simply deleted when someone finishes developing a new feature. The forks we’re talking about are when a significant number of developers in an Open-Source Software community, or a company, decide to branch off from the original project in an attempt to add substantial changes.
An example is Apache Calcite, an open-source SQL optimizer. The project has a mirror hosted at https://github.com/apache/calcite. Qubole has forked the project (https://github.com/qubole/calcite/) to add changes such as:
- Support for Apache Hive built-in functions
- Optimizations to Materialized Views
The rest of the blog will use Apache Calcite and Qubole Calcite as examples.
Merge (Or Rebase)
The default strategy is to use git merge. The basic flow is
git checkout https://github.com/qubole/calcite/ git remote add upstream https://github.com/apache/calcite git fetch upstream/master git merge upstream/master
In projects that have substantial and intrusive changes in the private fork, the merge is not a scalable option. For example, let us consider a scenario where intrusive changes are made to the materialization views module in Apache Calcite to add a feature. The feature consists of an initial commit and subsequent commits to fix bugs or additional features. These commits may be of varying complexity.
After a period of time, the materialization views module is redesigned to support a brand new feature by the open-source community. This feature also consists of an initial commit and subsequent fixes and additions. During a code merge, in the worst case, there will be a conflict in every commit of the private feature and the open-source feature.
The situation becomes untenable when there is a regular stream of commits in the master branch of a private fork and open source project and this scenario is scaled up to multiple features.
On the social front, no engineer wants to take up this responsibility as a full-time job.
Challenges
An incomplete list of challenges to keep a fork up to date with the canonical open source projects is:
- Merge Conflicts: Merge conflicts occur when there are competing changes in the same lines of code or if a file has been removed.
- Internal API changes: Projects are forked to make changes using internal APIs. There are no guarantees that internal APIs will be backward compatible.
- Dependency changes: A project may decide to use a different dependency for functionality. For example, the project may move to a different logging library.
- Dependency version changes: The open-source projects may change dependencies or their versions which may have a cascading effect on code in the fork.
- Coding style changes: If a project has coding standards, then any change in standards will have to be reapplied especially if the features & fixes will be contributed back.
- Logical changes: The project may decide to solve a problem using a different strategy which may have a cascading effect. For example, a project may change from thread pools to event-based concurrency.
Solution: Incremental Merge (or Rebase)
From the variety of challenges, it is obvious that there is no standard solution to solve all of them. Each issue has to be handled on a case-by-case basis.
Requirements
We came up with the following requirements to evaluate proposals to keep forks up to date:
- Continuous Integration & Alerts: Conflicts (like bugs) cannot be completely eliminated. Keep the volume manageable by using CI. CI should provide alerts as soon as there is a conflict.
- Incremental: It should be possible to checkpoint progress.
- Collaborative: Engineers should be able to work on conflicts in their domains at least in a sequential manner.
Open Source project forks contain custom changes. The changes can be managed as a sequence of patch files. Patch files can be applied one at a time, conflicts can be resolved and new patch files can be created. The ability to consider a patch file as a unit of work allows developers to make incremental progress and checkpoint their work.
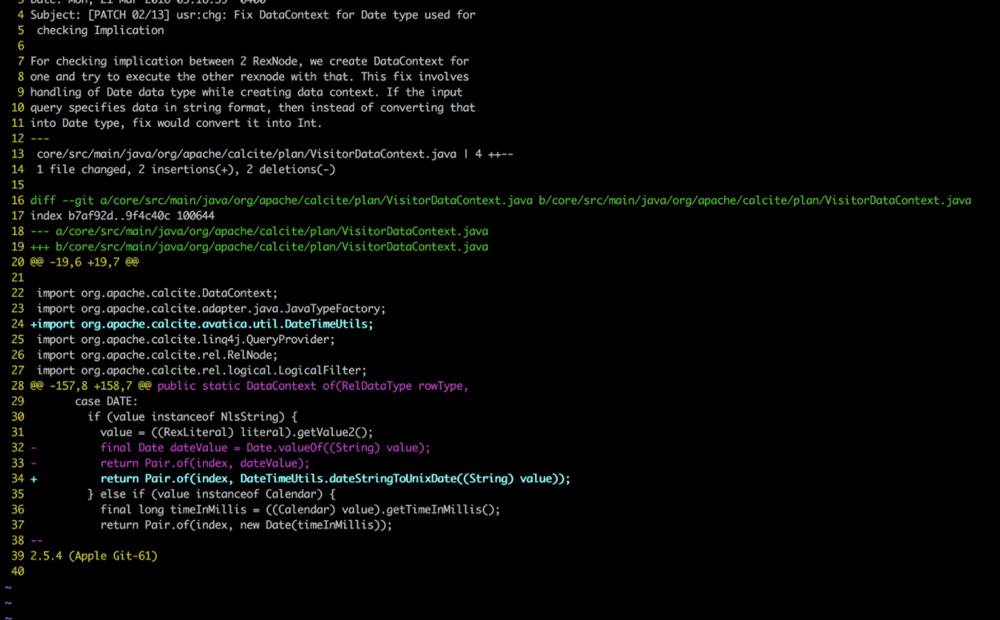
A typical patch file
Git provides git-format-patch to create patches and git-apply or git-am to apply patches. However, these functions are too low-level to be developer-friendly for large projects. Therefore we built git-patch to help developers create & manage patches as well as enable best practices to manage open source forks.
git-patch
git-patch helps manage the patch files using a structured workflow. git-patch supports the following development model:
- OSS project has a master branch and tracks releases with tags or branches.
- A forked project’s development branch is a copy of a release branch or tag.
For example, Qubole developers use the branch qds-1.13rc in qubole/calcite git fork. This branch was created from the release calcite-1.13.0.
Similar to how Git uses .git as a working directory, git-patch uses .patch as a working directory. .patch is stored in a branch that tracks the OSS master branch. For example, .patch is stored in the oss-master branch in qubole-calcite.
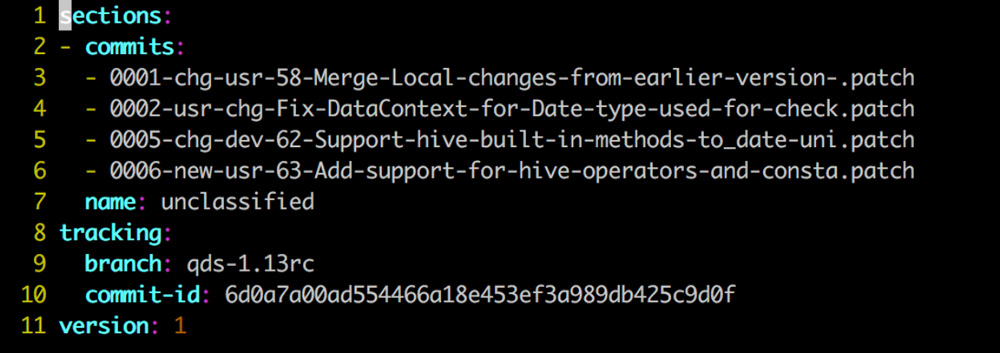
Configuration information in .patch directory
Once git-patch is set up, it supports the following workflow:
- Apply and test patches on the HEAD of apache/calcite/master.
- git-patch fails if any of the patches cannot be applied, typically because of conflicts.
- The developer fixes conflicts and generates new patches with the help of git-patch.
git-patch can be wrapped in a CI system like Jenkins to help detect failures immediately.
Unlike git-rebase or git-merge, git-patch allows developers to the checkpoint and commit work even though only a subset of conflicts are resolved. Checkpointing helps in stepping away from the task and making incremental progress. It also helps to transfer the task among experts in different areas. git-patch can checkpoint because it uses patch files instead of commits.
Prompt alerts and checkpointing have helped developers not get bogged down by upgrade tasks every time a new release is planned. After git-patch was adopted, a new release with open source and custom patches is available within an hour. Most of the time is taken in running unit tests.
git-patch also contains commands to compact patches. For example, assume a feature consists of an initial commit followed by 4 bug fixes. After a few months, once there is no active development on a feature, 5 commits (1 initial + 4 bug fixes) can be combined into a single patch file. Compaction helps to manage the number of patch files that need to be maintained.
Conclusion
git-patch has helped teams at Qubole that work with open source forks to reliably keep up to date with their respective community. Customers on QDS can use the latest versions of Apache Spark, Apache Airflow, and Presto on QDS along with all the optimizations for public cloud platforms unique to Qubole. If you or your team maintain a fork of a project and are facing similar issues, then check out the project on GitHub or PyPi. If you have any questions or discuss improvements, please contact us through GitHub Issues.
This is one of the many ways Qubole helps shape how people use data today and in the future. If you are interested in joining a fast-paced team and working on cool projects at the intersection of Big Data and Cloud Infrastructure please check out our open positions: https://www.qubole.com/company/careers/



