We’re excited to announce that Apache Hadoop 2.6.0, the latest stable release* of Apache Hadoop, is now generally available on Qubole. Hadoop 2.6.0 is compatible with all of the usual services that Qubole offers, including Spark, Hive, Pig, and MapReduce. In addition, the optimizations that we’ve made for operating in the cloud, such as auto-scaling and spot instances, still apply.
* Apache Hadoop 2.7.0 is available but not yet ready for production use.
Hadoop 2.6.0, as with all Hadoop 2.x releases, includes enhancements that allow for better compute utilization. Because there are no longer individual slots for map and reduce, map and reduce containers can utilize the resources better as they can occupy any available container present in the system rather than a “slot”. In Hadoop 2, the functionality of Job Tracker has also been split into Resource Manager (RM) and Application Master (AM), which results in a lesser load on the RM for very large clusters. In addition, you can now run Spark and Hive jobs on the same cluster as both are applications built on YARN.
Moving to Hadoop 2.6.0 also opens up more product options for us. For instance, in the future, we may support Apache Tez as an alternate execution engine to provide even better performance for Hive queries.
All new Qubole customers already have a Hadoop 2 cluster configured by default with the cluster label “hadoop2”. In addition, you can easily configure new clusters to use Hadoop 2 through the Control Panel in the Qubole Web Interface. While creating the cluster configuration, simply choose “Hadoop 2” in the Cluster Type drop-down menu.
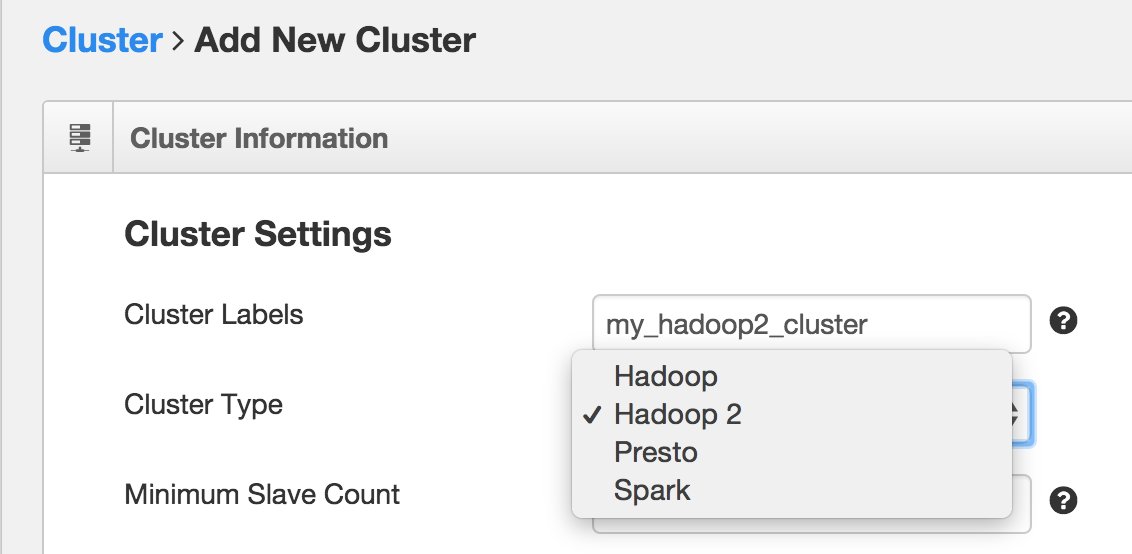
We look forward to seeing how you plan on using Hadoop 2.6.0. You can read more about this topic in our User Guide.



