Data lakes are at the heart of digital transformation in enterprises. As more organizations run analytics, machine learning, and ETL workloads on the data residing in the data lakes, they come with privacy and integrity risk. Organizations have the urgency to preserve privacy and control access to this data as per regulations such as GDPR (Right to be Forgotten) and CCPA (Right to Be Erased) and other frameworks. As these regulations have a deadline for enterprises to get compliant, organizations are always looking for faster and scalable ways to get their data lake(s) compliant. Organizations put different measures for data governance at multiple levels from data security to data accessibility. But current high-level file-level security measures and accepted best practices are not sufficient for data privacy requirements. Qubole provides built-in Apache Ranger and ACID support for data privacy and integrity respectively. The platform supports Apache Ranger and ACID for Presto, Hive, and Spark.
For data privacy, Apache Ranger provides granular data access controls and the ability to mask data. It provides centralized security administration to manage all security-related tasks and fine-grained authorization to do a specific action and/or operation. With Apache Ranger, the authorization methods can be standardized for the underlying engine. The role-based access control and attribute-based access control is supported to help leverage existing RBAC solution implemented in the organization. Lastly, auditing capabilities help to see user access and administrative actions.
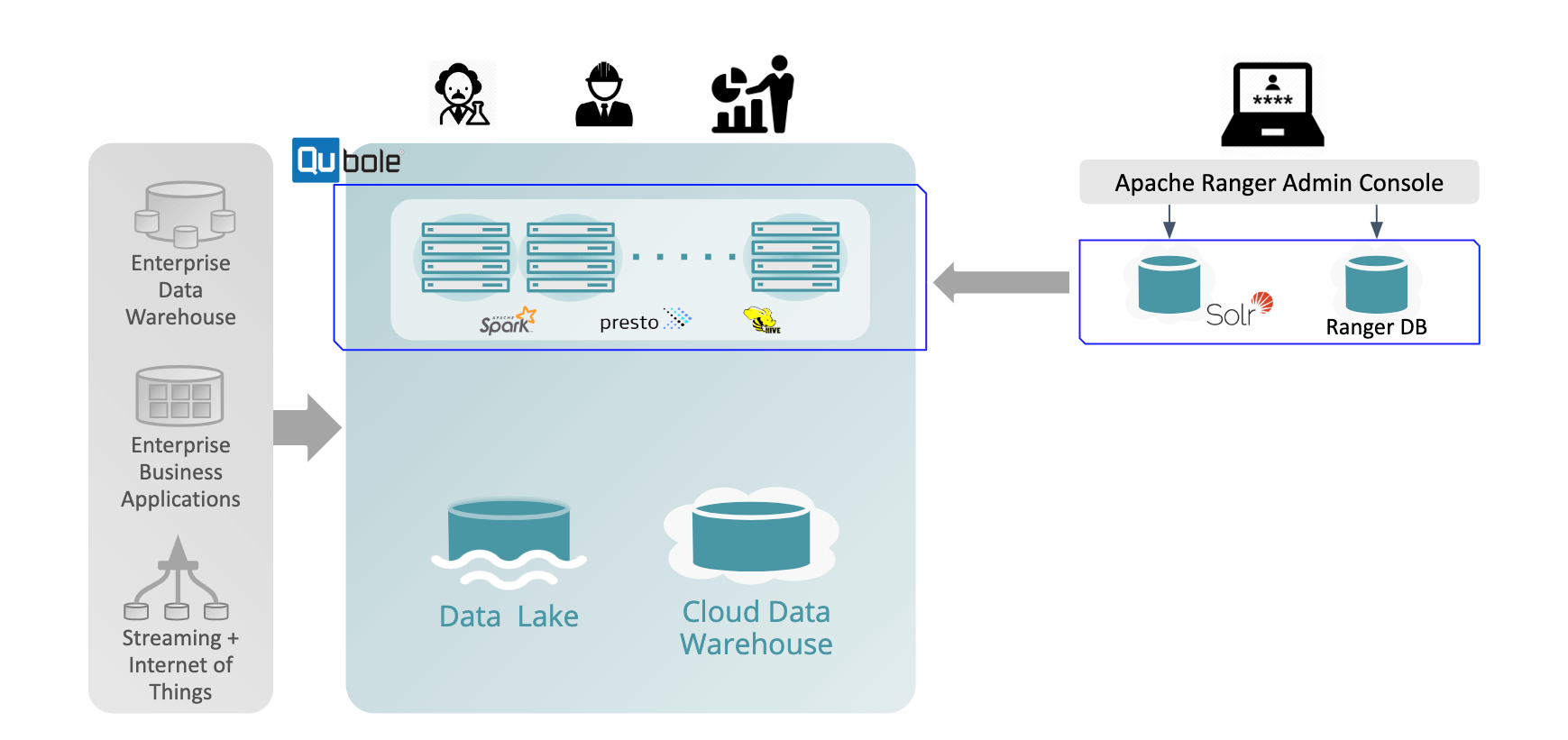

Figure 1: Apache Ranger on Qubole

For data integrity, ACID transactions help data engineers avoid lost updates, dirty reads, and stale reads and enforce app-specific integrity constraints. Data integrity is maintained in the data lake when concurrent users access the data lake to read and write data simultaneously. The ACID transaction helps with the right to be forgotten and the right to be erased by making sure that data in the data lake is current and if asked to be deleted, is deleted.
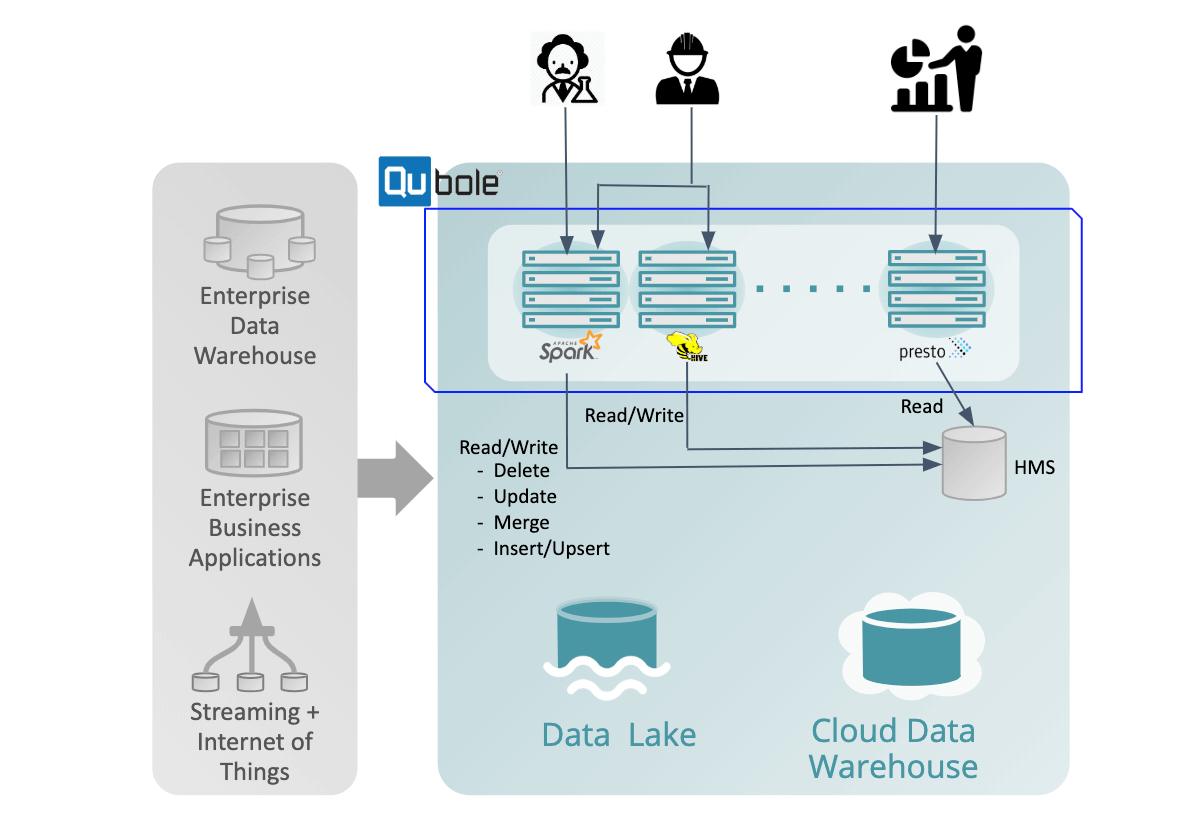
Figure 2: ACID Transactions with Qubole

Apache Ranger and ACID’s open-source roots make sure that they are deployment-proven and community strengthened. Using these open-source solutions as a built-in feature of Qubole data service makes them a part of everyday workflow instead of an afterthought point fix solution. Following are a few improvements that Qubole has made to Apache Ranger and ACID for their enterprise customers:
- Efficient updates, and deletes to data: Users can make inserts, updates, and deletes on transactional Hive Tables—defined over files in a data lake via Apache Hive—and query the same via Apache Spark or Presto. The traditional approach for such updates and deletions has been to overwrite the data at a partition level. This approach requires a rewrite of large amounts of data for even a few rows changed— and thus fails to scale efficiently. Qubole writes only to changed rows thus providing faster rewrites, updates, and deletes.
- Direct writes to the final location on cloud storage: Apache Hive writes data to temporary locations first and renames it to the final location in a final commit step. Renames are expensive operations in cloud storage systems like AWS’ S3. In order to reduce the performance impact due to this impedance mismatch, Qubole writes directly to the final location and avoids the expensive rename step.
- Atomic operations to rename directories on cloud storage: Directory renames being not atomic can make partial data visible in the destination directory when using the open-source version. As a result compactions (which perform a rename) are unsafe to run concurrently with a read operation. Qubole provides atomic operation using a commit marker in the destination directory for the waiting reader.
- Single UI/Solution for multiple engines: Qubole provides a single and same UI for using ACID or Apache Ranger across multiple engines. Organizations don’t need to learn specific ways to leverage Apache Ranger or ACID with Spark, Presto, or Hive. They don’t need to learn any specific configurations for each engine to implement separate access controls, do performance tune-ups, and delete/merge/update operations. By making Apache Spark and ACID part of Qubole Data Service, Qubole lets the organizations focus on building data pipelines, ad-hoc SQL queries, and ML workbenches at scale without performance impact.
- Use existing controls and infrastructure: Users using Apache Ranger or built-in ACID features currently have to use specific tools for each engine and build custom scripts for it. With Qubole’s RBAC integrations of Active Directory, LDAP, and SAML2.0, organizations can leverage their existing RBAC solutions to manage user access to the data lakes.
Qubole ACID and Apache Ranger address distinct requirements of granular data access control and granular delete/merge/update respectively. Qubole Data Services help organizations well govern data in their data lakes across multiple engines and future proof for newer regulations while dealing with the massive volume and velocity of data.



