This is a guest post written by Rory Sawyer, Software Engineer at MediaMath
Here at MediaMath, we’re quite fond of data. It would be surprising to hear someone say they’re not fond of data, of course, but we’ve spent the last 18 months proving to ourselves and our clients that we really mean it. Our company is built around driving concrete, measurable results, and our clients – both internal and external – have sophisticated analytics teams that want access to the data we generate for their own analysis, owned marketing, budgeting, and more. In this post, we will describe the journey from a data warehouse to a data platform and the success of ditching our on-premises hardware. It has enabled our business to grow and for different personas in our organization to innovate, be more productive and expand their roles and how they impact the overall business.
What we deal with
MediaMath sees roughly 180 billion impression opportunities a day (coming out to 3M QPS at the peak) and the data we end up keeping takes up over 3Tb of (compressed) space per day. Because MediaMath is buying ad space, a large chunk of this data represents financial transactions so every record counts. For this reason, we have always loved our logs. They are our greatest source of insights but for a long time were among our least accessible assets.
The beginning(ish)
This story in around 2013, about 6 years after MediaMath’s creation. At the time, this is what our data warehouse architecture looked like:
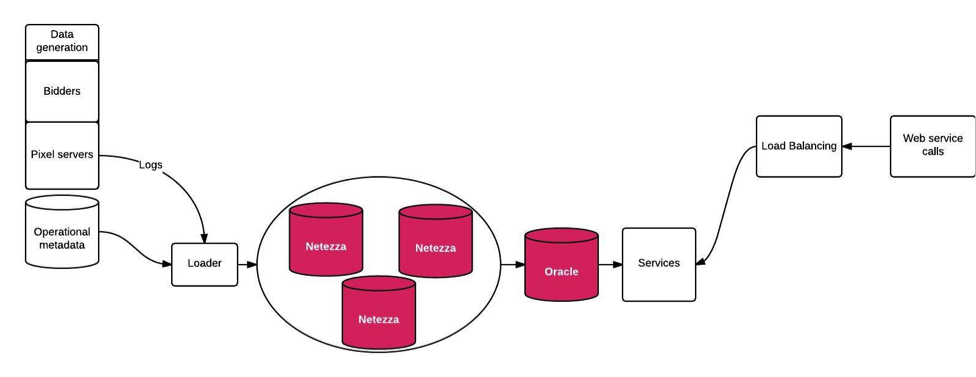
We had three Netezza servers storing and processing all of the data generated by other teams. Netezza would then push reports to a fleet of Oracle servers that acted as our data mart. Access to Netezza was tightly controlled and ruthlessly monitored and so only a privileged few outsides of the data warehouse team were granted access. Even then, those few were running their analyses side-by-side with production jobs. This meant that simply extracting logs – no aggregation, nothing fancy (or useful) – would cause production reporting delays. Similarly, developers often had to develop and QA their jobs in production. On top of that, they had to act as gatekeepers of this system, warding off those who dared to run queries. So developers and consumers alike were frustrated, and that’s even without asking the question of how this was going to scale. (spoiler: it doesn’t)
Data Liberation
It was around the end of 2013 that a process started at MediaMath that we would later call Data Liberation. The goal of this was to alleviate the pain points from both the user and developer sides while also providing a solution for scalability. Data Liberation was about separating storage and computation. To do this, we moved our warehouse into the cloud, using Amazon Web Services (AWS) as our provider of choice. Our usage eventually coalesced around three main products: Simple Storage Service (S3), a key/value object store; Elastic Map Reduce (EMR), which provides transient Hadoop clusters; and Redshift, a columnar databased that provided efficient querying on large datasets. S3 and EMR would replace Netezza, and Redshift replaced Oracle.
Among the advantages this new warehouse came with was resource flexibility. We could now scale our resources in lockstep with our data volume, use EC2 spot instances for cheap computation, and worry about our business problems instead of our infrastructure. What’s better, now that storage and computation were separated we could give reliable access along the way. Here’s a quick look at what our new warehouse looks like:
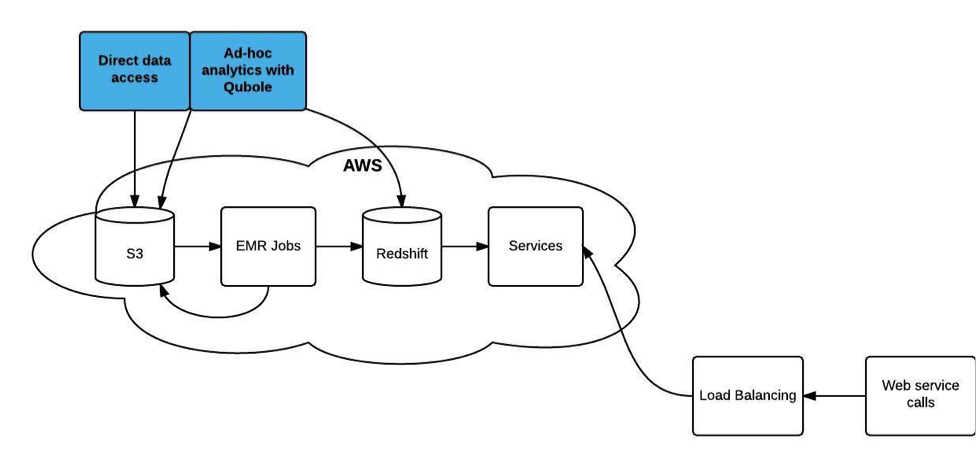
Liberating MediaMath’s Data with the Cloud
A change of pace
This architecture enabled rapid development as we moved from SQL to Scala (we use Scalding extensively). The separation of storage and computation reduced the complexity of managing development and QA environments tremendously. Production, development, and ad-hoc analytics processes could run on the same source data with no duplication and without bumping elbows. This has helped us get past the “big data inertia” that kept us sluggish.
The Organizational Impact of Decoupling Storage and Compute
The separation of the individual pieces of our pipeline also allowed us to tighten up guarantees on the components and create a stable product offering of our log-level data. This transformed the user experience of our data platform. Access to logs is no longer a privilege but a right, and the platform provides flexibility in how users interact with it. Clients are able to choose a query method that suits them, and we’ve partnered with Qubole to make the platform accessible to users beyond the technology side of the organization. Qubole provides various data processing systems as a service and leverages AWS to provide scalable clusters that can be launched with a few clicks.
The migration was not without its pain points. Spot Instances – left-over server inventory purchased by bidding – would occasionally be unavailable, and we had to tune our jobs to use more readily available instances (or fork over more money for the ones we really wanted). Additionally, the migration was not a complete forklift over to the new system. We kept (and are still keeping) both systems running, so an upfront cost was paid to keep these in sync. We managed this by keeping fact tables of processed files to make sure each system had the same input data. This decision, while incurring the overhead of keeping two systems running, allowed us to move over in pieces while delivering new reporting features.
MediaMath Grows into the Cloud
Where we’re at
Data Liberation marked an important move forward in our approach to data processing at MediaMath. We needed storage to be centralized, but computation to be distributed. I’m talking about teams, not machines, and today we have data engineers all across the organization. The transient infrastructure that “the cloud” provides removes both friction and tech debt as we can evolve our processes and ideas before committing to hardware and licenses and maintenance and so on. We feel confident that we’ve left behind the walled-off world of warehousing and now live out in the open as a solid foundation for data-intensive applications at MediaMath.
The Effects of Data Liberation on our users and Business
Data liberation has allowed us to expand our customer base and grow the business. In the 18 months since beginning our Data Liberation journey in 2014, MediaMath has grown its employees from approximately 350 to 650 employees to service this expansion. Prior to this process our sole consumers of log-level data were a handful of data analysts from the client and partner analytics teams, and the tools they used were almost entirely SQL. Data Liberation expanded our user base by offering flexibility and ease of use in the form of AWS and Qubole. In 2016, we now have 21 external clients with log-level API access, and 91 internal clients that access data through Qubole, all of which have significantly increased the use of this data in day-to-day decisions across teams and client users.
Empowering Users with Qubole and AWS
Data Liberation has also allowed our Data Platform team to take a “hands-off” approach to the process – we let the consumers use whichever tools they want. The availability of data and the flexibility of the platform have created new roles and enabled different roles to be more productive and enhance what they can provide the business. Below are some examples of teams, tools, and use cases that have benefited from Data Liberation:
Data Science – Our data science team did not exist before we were able to unlock data with our new platform approach. Now MediaMath can do a much better and more granular analysis of spend on media purchasing over time. Using ad hoc analysis and technologies like Spark and Hive on log-level data on Qubole our data scientists can test/evolve our optimization algorithms. Having log-level data available makes it easier to analyze spending per impression over a period of time. Our customers are being better served because MediaMath can consistently extend and improve the value of their media spend.
Client Analytics – Our client analytics analysts with SQL skillsets have been able to utilize Hive on Qubole as well as data sets in AWS Redshift to deliver custom, tailored reporting and analytics to each client. In order to provide this level of customized and detailed reports, analysts needed log-level data. Our new liberated data platform has enabled analysts to better serve clients and provide reports with their organization-specific KPIs or breakouts.
Engineering – In the past engineering had to do QA in the production environment since there was no specific dev/test environment—there was a regular bottleneck for what we could test, and QA priority was given to development that was more conservative. This limited the quantity of development and innovation on the existing platform. With the new MediaMath data platform, the engineering team could now use Hive to QA their work and engage in open-ended exploration. This would have put too much strain on our old architecture. The quality of development QA has increased, development productivity has increased, is more responsive to business initiatives, and release risk has been reduced for the organization. With renewed energy within its development and engineering culture, MediaMath is looking to grow its engineering team by 50% in 2016.
Product Management – This team has been able to use Hive and ad-hoc queries to examine product usage and inform product roadmaps. These teams need to be able to combine log-level data with specific metadata they are tracking and keeping in order to parse usage patterns in meaningful ways. The product team is also contributing additional metadata to the product platform. The new data platform has also enabled MediaMath to develop new products and services to end customers. We are in trials with a new product that leverages the self-service aspects of Qubole to allow customers to develop their own queries off of exposed data sets. This opens up new opportunities for revenue and ways for a segment of our clients to be better served.
While still a work in progress, our journey to make our data lifeline more available has provided MediaMath with a foundation for growth. We are leveraging the elasticity of the AWS cloud, and innovative tools like Qubole and providing our engineers, data scientist, and product managers the freedom to innovate on our core algorithms and provide customers the information they need to make better marketing decisions. We believe our experience could be a model and inspiration to other enterprises making this similar change.



