Data Caching for Performance and Scalability
- Home >
- Product >
- CLOUD-NATIVE ARCHITECTURE >
- Data Caching
Data Caching
Qubole’s data caching feature automates the movement of data for performance optimization. It automatically determines the right set of data to cache in the cluster so that interactive / ad hoc, batch, or scheduled queries run faster and don’t need to retrieve data from the source for each query.
Additionally, Qubole’s data caching also makes optimal use of ORC, Parquet, and Avro data formats – minimizing the amount of data retrieved by selecting only the required columns.
Shared Metadata Catalog
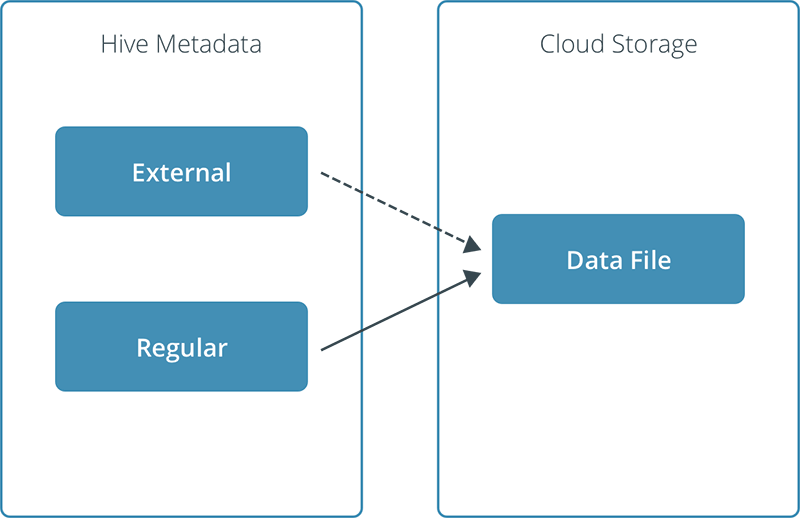
Qubole provides the ability to create schema tables for files in cloud storage inside of Qubole’s Hive Metadata Catalog. These schema tables serve as an abstraction layer on top of the file system and provide a table structure for SQL queries. With this schema in place, users can write SQL queries from Qubole against data that is physically on a cloud file system.
In addition to caching data, Qubole can also cache table statistics to further improve performance. Qubole offers multiple methods for collecting table statistics. Any engine or framework running on Qubole will generate more efficient query plans when the Hive Metadata contains table statistics.


