Democratize Streaming Analytics
Democratize Streaming Analytics
Infinite scale and possibilities with Qubole Data Lake
Qubole Data Lake provides ready availability of data that matters to the people that need it by interfacing directly with their data sets through profiles set up for each type of workload and role.
Data Engineers can leverage Spark to orchestrate the ETL using Airflow, Data Scientists can focus on leveraging existing libraries and creating code accordingly, whilst Business Analysts can leverage Presto to query their meta store
All of this is achieved through Qubole Pipelines Service – a Stream Processing Service that addresses real-time ingestion, decision, machine learning, and reporting use-cases.
Whether you’re a data engineer, an analyst, or a data scientist, contact Quoble today and try different examples of Spark and Presto today!
[preEmptive_forms id=”45″]
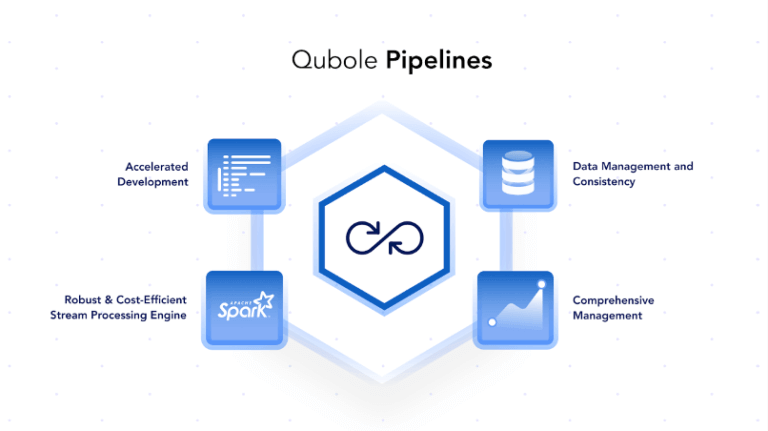
Accelerated Development Cycle: Numerous built-in connectors, code generation wizard, dry run framework, and quick-start options accelerate the software development lifecycle. A pipeline can be developed within minutes without writing even a single line of code and be deployed instantly.
Data Management and Consistency: The Pipelines Service uses Qubole’s ACID framework to compact data in the background and allow readers to query the latest data in a performant yet consistent manner.
Robust and Cost-Efficient Stream Processing Engine: We chose Apache Spark Structured Streaming as our streaming engine of choice and made numerous enhancements – Rocksdb State Storage, Direct Writes, Executor Taint Management – to reliably productionize long-running streaming applications.
Comprehensive Operational Management: Broad set of APIs and Interfaces for engineers to holistically manage the lifecycle of various applications and get continuous operational insights.
Infinite scale and possibilities with Qubole Data Lake



