In one of our previous blog posts on AIR Infrastructure, we discussed the various data sources for AIR and the architecture for collecting these data from various engines. In this blog, we will take a closer look at how the data is collected and transformed into various insights and recommendations using Qubole Airflow. We will take a step further and discuss our experiences of using Apache Airflow as the workflow manager for orchestrating the ETL pipelines.
Recap On Qubole AIR:
AIR is an intelligence platform that provides insights and recommendations based on data collected from Hive, Spark, and Presto clusters. The following data-driven features are currently available:
- Data Discovery
- Insights
- Recommendations
For a detailed feature list provided by AIR, you can refer to this blog post.
Challenges Involved in Building AIR
- Variety of Data: As mentioned in the blog regarding data sources for AIR, the main source of data for the platform is the workloads submitted by the users. In addition to this, each execution engine sends the execution metrics when this SQL, machine learning, deep learning, or scala jobs are executed.
- Different SQL Grammar: As Qubole supports multiple engines we get SQL queries from Apache Hive, Apache Spark, and Presto each supporting its own syntax of SQL. To add another dimension to the complexity we have multiple accounts using multiple versions of the engines and the grammar of the SQL differs from one version to another. To put some numbers around the complexity of the task, we require a system that should be able to handle 250,000 queries running across 2000 clusters authored by various customers on a daily basis.
- Disjointed Execution Metrics: Each execution engine generates and publishes a set of metrics to the AIR platform during the execution phase of the query. The ingestion pipeline is designed with such flexibility that the engines can publish the metrics at any level of granularity. This flexibility allows the engines to push the set of metrics they seem will be useful for debugging the query execution. For example, Qubole Spark sends the metrics on a per executor basis whereas Hive sends all the metrics combined as one single payload at the end of query execution.
- Connected Data: Data is ingested into the AIR platform throughout all the execution phases of a query. Other than query execution metrics another main source of data ingested to the AIR platform is the cluster level data. All these various sources can be combined to generate various insights and recommendations. It is a challenge to combine these two streams which have different rates of ingestion.
- Volume Of Data: The second source of data for the platform is the execution metrics provided by the engines during runtime. As of today, around 10GB of data is being ingested into the AIR platform on a daily basis across all data sources and newer data sources are added to the platform on an ongoing basis. Typically the analysis that we do is over a 90 days period which translates to processing 1TB of data daily. The freshness of the data is another issue to tackle at this scale. The ingestion pipeline can encounter lag at times and the platform has to be sophisticated enough to handle this lag accordingly.
Implementation
Internally the AIR platform is deployed as another Qubole account. We dogfood Qubole to run the data platform for AIR. Qubole provides us Hive, Spark, and Presto clusters along with Apache Airflow for workload management. On this platform, we run multiple ETL pipelines that implement a series of data transformations (explained in later sections) to break down the user-submitted workloads to an analyzable format.
The above diagram shows all the ETL pipelines run using Apache Airflow as part of the Qubole Data Warehouse. All the ETL workloads are submitted to QDS via the Qubole Operator. Qubole Operator is available in the open-source Apache Airflow distribution which allows you to submit various types of commands like Hive Command, Spark Command, DataImport Command, and DataExport Command to QDS. This abstraction of the Qubole Operator allows the developer to write the ETL in the engine of his/her choice and the Qubole Operator takes care of the lifecycle management of the command.
Why we chose Apache Airflow
We chose Apache Airflow as our workflow management tool for Operator Abstraction, ability to code ETL pipelines in Python, reliability, extensibility, community support, and failure handling. Another strong factor is the tight integration Qubole has with Apache Airflow. In one of our previous blog posts, we talked about releasing Apache Airflow as a part of the Qubole Data Service. Following are some compelling features provided by Apache Airflow that made AIR development simpler.
- Dynamic Dag Generation: One of the cool features of Apache Airflow is you can author your DAG as Python code. This implies that you can use Python’s language features to generate DAGs programmatically. For example, we save the list of account ids for which the AIR pipeline is enabled as an Apache Airflow variable. The ETL code implemented in Python uses a for loop to generate a Qubole Operator for each account and joins these to an END operator.
- Inter-Dag Dependency: Apache Airflow provides TriggerDagRunOperator to trigger another ETL from within an ETL. This has helped us to break down the transformations into simple logical units and encapsulate each unit as a DAG. Using the TriggerDagRunOperator the downstream transformation can be triggered once the current transformation is finished and verified to be correct.
- Failure Handling: Apache Airflow has a couple of features that help to deal with failures in the ETL pipelines. By default, Apache Airflow is designed to send an email alert in case a task fails. It also provides on_failure_callback which can be specified for every operator and can execute a Python function in the case the operator fails. We have leveraged this to create slack notifications for failures.
- BackFill: Data Transformations are error-prone and might need multiple iterations to get to a correct state. The backfill feature of Apache Airflow allows us to go back and correct the older data by running a single command.
- Check Operator For Data Quality: A data warehouse worth can be determined by the quality of data it possesses. The type of applications that are being built on the AIR platform enforces the data to be of the highest quality. As a part of the IRIS project for data quality, we evaluated and extended the Check Operator. The initial results from integrating Check Operator in our ETL pipelines look very promising. We will say more about the IRIS project in a separate blog post.
A full feature list of Apache Airflow operators and features can be found here.
ETL pipelines and Data Transformations in AIR
In this section, we will take a look at the broad categories of ETL pipelines that are part of the AIR platform.
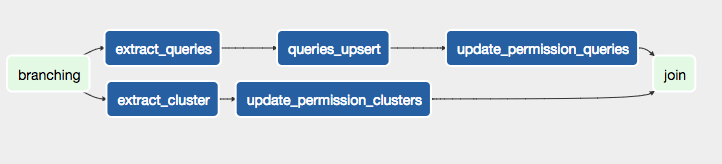
- Data Ingestion: This category of ETL pipelines is responsible for ingesting the data from various sources into the AIR data warehouse. For example, QDS business logic is powered by a MySQL database that contains information like accounts, users, clusters and their lifetimes, machines, and their lifetimes as part of running clusters. The DAG shown in the figure below is an example of an ETL pipeline that downloads data from tables in the MySQL database. It uses a Qubole Operator in Data Import mode. For tables that are small in size, the entire table is downloaded daily. Whereas the tables that are large, updated, and new rows are extracted daily into a date partitioned table.

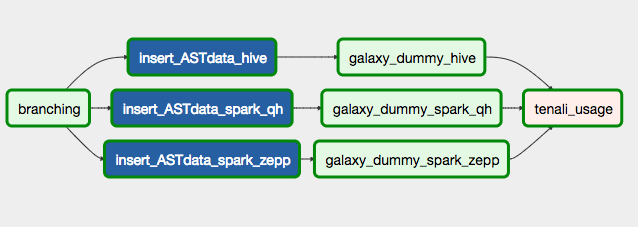
- Transformation: This category of ETL pipelines reads the data prepared by the ingestion phase and performs a series of transformations to prepare the data for applications like Data Discovery, Insights, and Recommendations. It comprises Hive and Spark Commands run using the Qubole Operator. For example, Parse Tree Generation DAG processes SQL queries submitted to Hive, Spark, or Presto clusters and stores their parse trees. It uses a Java Hive UDF. The UDF has engine-specific parsers to translate the query from a raw sequence of characters to an Abstract Syntax Tree. The internals of the UDF on how the translation is done is beyond the scope of this discussion and will be discussed in a later blog.

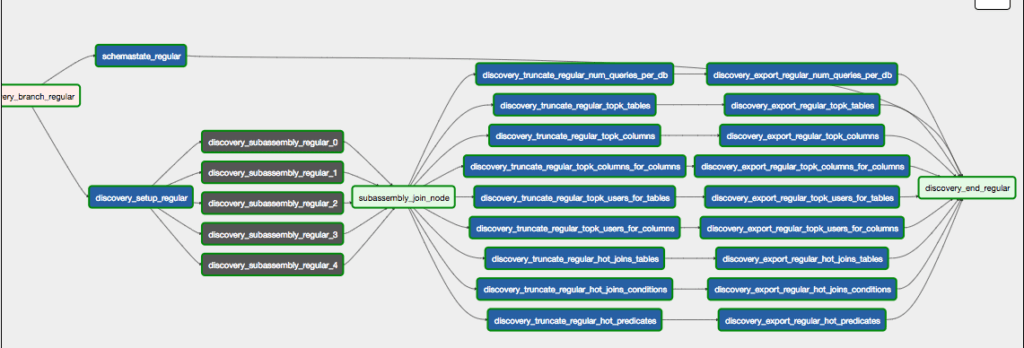
- Extraction & Aggregation: This category of ETL pipelines is responsible for reading the transformed data and generating the final insights and recommendations for AIR. Typically they end with a Qubole Operator in the Data Export mode to export the results to a MySQL database. Qubole AIR UI renders the information in the MySQL database. For example, DataDiscovery DAG is responsible for traversing the parse tree and generating useful insights like frequently used tables, columns, joins, and so on.

Apache Airflow Pits and Tricks
The journey of using Apache Airflow to orchestrate the ETL pipelines has been quite adventurous and knowledgeable. Here are some key takeaways from our journey with Apache Airflow:
- SubDag – a Boon & Curse:
SubDag for Parallelism: SubDag is an excellent feature of Apache Airflow that allows a repeating pattern to be represented in a clean manner. We used SubDag to run a series of queries with different parameters eg: a list of account_id’s for which a query is supposed to run. This helped us circumvent a whole bunch of issues from the execution layer and provided isolation in case the queries failed.
Beware of too many SubDag instances: However, too many SubDag instances in your flow can also lead to issues. A SubDag instance occupies an executor slot till all the tasks have succeeded. This can lead to a deadlock situation if the number of running SubDag instances is equal to the number of executor slots you have. In this case, all executors are busy running a SubDag and the queued tasks will be waiting for an executor slot to free up. The following open source JIRA references the above-mentioned problem(https://issues.apache.org/jira/browse/AIRFLOW-74). - Scheduler Code Path: Apache Airflow has a scheduler process that keeps executing the Python DAG files in the DAGs directory to check for new tasks to be scheduled and executed. So take absolute care not to write any redundant code other than the operator definition and the dependency statements in the DAG file. For eg, if you have a code snippet for downloading a config file from Amazon s3 outside an Operator then this snippet will be executed every time a scheduler process is executed which can cause unexpected side effects.
- Caution on Python Callable In Python Operator: The Python callable field of the Python Operator should be filled with just the function name without the function call braces. For example, use fn and not fn(). If written with the braces the Python function will be executed each time the scheduler process runs and can introduce an unwanted load on the machine.
- Short Circuit Operator and Wait For Downstream: Wait For Downstream is a useful feature of Apache Airflow which comes in handy when all the tasks downstream to an operator should be executed before the next instance of the same operator shall be executed in the next scheduled DAG run. However, if the feature is applied to Short Circuit Operator which returns false and skips all the downstream tasks then Apache Airflow fails to schedule the tasks from the next DAG run as wait for downstream expects all the downstream tasks to be successful.
What’s Next?
Apache Airflow is an excellent way to orchestrate your ETL pipelines. However, more features are required on the operational aspects of using Apache Airflow. For example, the means to deploy a DAG onto Apache Airflow is to copy the Python script into the DAG’s directory. Now if you are providing a platform for applications to write their ETL pipelines, autonomous management of the pipelines is a must. Configuration management also needs to be versioned and tracked. We want to also use CI(Continuous Integration) and CD(Continuous Deploy) to automate change management. We strongly believe that CI/CD is a must-have in the ETL world. We have built an internal tool that provides some of these functionalities on top of Apache Airflow. We will talk more about it in a separate blog post.
Conclusion
In this blog post, we have described our experience of using Qubole Airflow for orchestrating the ETL pipelines powering the AIR platform. We are constantly evolving the platform to add more features. If you are interested in joining a fast-paced team and working on interesting projects involving data please apply on the Qubole Careers Page.



