This is Part 3 of 3
Snowflake Spark Connector
Snowflake and Qubole have partnered to bring a new level of integrated product capabilities that make it easier and faster to build and deploy Machine Learning (ML) and Artificial Intelligence (AI) models in Apache Spark using data stored in Snowflake and big data sources.
In this last blog of three, we cover how to use Apache Spark on Qubole to prepare external data and write it into Snowflake.
The blog series covers the use cases directly served by the Qubole–Snowflake integration. The first blog discussed how to get started with ML in Apache Spark using data stored in Snowflake. Blog two covered how data engineers can use Qubole to read data in Snowflake for advanced data preparation, such as data wrangling, data augmentation, and advanced ETL to refine existing Snowflake data sets.
Data Lake Storage
Data lakes provide the advantage of storing massive amounts of data at an affordable cost, in any format and without worrying about the schema, because the schema is decided upon reading. Because of the cost-effectiveness of data lakes, there is never any need to throw away or archive the raw data. It is always there should any of users want to revisit it.
Big Data Analytics
Successful big data analysis requires more than just the raw data in the data lake. It requires good, high-quality data specific to the different business needs. That involves taking the raw data that has been ingested in the data lake, altering and modifying files as needed, and preparing it to make it consumable for analysis. Data Engineers need to create new datasets by combining, refining, and massaging the raw data in the data lake. Since the amount of data in the data lake is massive, Data engineers rely on cluster computing frameworks with in-memory primitives, like Spark that make the advanced data preparation run faster and the process easier
The Snowflake-Qubole integration allows customers to derive business-specific data sets using Spark and store them in a scalable and performant Snowflake virtual data warehouse. The combination of Snowflake and Qubole allows customers to bring the data lake and the data warehouse together for all data, all analytics, and all access
The diagram below explains how data engineers can do advanced data preparation in Apache Spark using external data and write it into Snowflake.
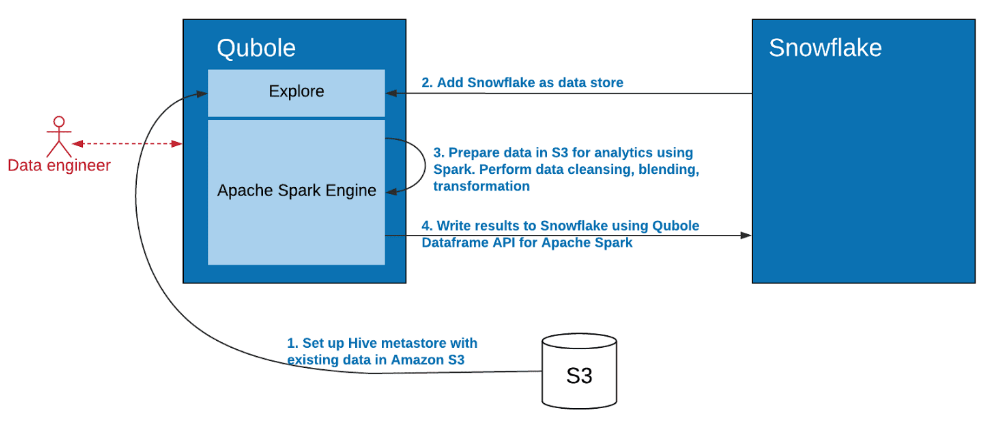
Snowflake Integration
The first step is to connect to a Snowflake virtual Data Warehouse from the Qubole Data Service (QDS). We described the details of how to set up a Snowflake Data Store in the first blog of the series.
Spark Clusters
Typically data engineers use Apache Spark SQL to query data stored in the cloud, or simply load data through an AWS S3 path. But there’s a better way…using Qubole Apache Spark clusters to store and load data. QDS optimizes the process by generating and storing metadata by the user. In addition, it provides a unique set of useful features, such as:
- High-performance Apache Spark engine tuned for cloud storage
- Enhanced autoscaling for up– or downscaling compute resources based on workloads
- High-speed table catalog build mechanism for partitioned tables
- Fast open-source caching of file systems with Apache Spark + RubiX
- Ability to run Apache Spark on heterogeneous clusters
- Enhanced support for AWS Spot Instances, including early detection of Spot loss and placing Executors from lost nodes under a graceful shutdown.
Snowflake Data
Once data is manipulated and a new data set is created, data engineers can write the data to Snowflake using the same data frame API interface, indicating in the last parameter the destination table name in Snowflake. It is important to note that you can write the prepared data directly to Snowflake using the data frame API, without having to stage it in S3 for subsequent uploading to Snowflake. This makes the data pipeline more efficient and reduces the time to make the data available to business users for analysis.
Below is a sample Scala code snippet for writing data to Snowflake:
Df.write
.option("sfDatabase","")
.snowflake("","", "")The Qubole–Snowflake integration allows data scientists and other users to:
- Leverage the scalability of the cloud. Both Snowflake and Qubole separate compute from storage, allowing organizations to scale up or down computing resources for data processing as needed. Qubole’s workload-aware autoscaling automatically determines the optimal size of the Apache Spark cluster based on the workload.
- Securely store connection credentials. When Snowflake is added as a Qubole data store, credentials are stored encrypted and they do not need to be exposed in plain text in Notebooks. This gives users access to reliably secure collaboration.
- Configure and start-up Apache Spark clusters hassle-free. The Snowflake Connector is preloaded with Qubole Apache Spark clusters, eliminating manual steps to bootstrap or load Snowflake JAR files into Apache Spark.
Snowflake Data Engineering
The integration between Qubole and Snowflake provides data engineers a secure and easy way to perform advanced data preparation in Apache Spark using data in the data lake and the language that best suits their need (Java, Python, Scala, or R), and write the refined datasets to Snowflake to do allow uses do advanced analytics, reports, and dashboard.
Qubole removes the manual steps needed to configure Apache Spark with Snowflake, making it more secure by storing encrypted user credentials, eliminating the need to expose them as plain text, and automatically managing and scaling clusters based on workloads.
For more information on Machine Learning in Qubole, visit the Qubole Blog. To learn more about Snowflake, visit the Snowflake Blog. Or use the references below
- Qubole-Snowflake Integration Guide
- Setup Snowflake Datastore
- Running Apache Spark Applications on QDS
- How to use Apache Spark in Qubole


