We’re excited to announce that Qubole can now run Hadoop, Spark, and Presto clusters with zero local disk storage. We now support AWS M4 and C4 instance types, which do not include local disk storage and instead utilize either S3 (for long-lived data) or EBS (network-attached disk storage for holding intermediate and temporary data) for storage.
4th Generation AWS instances
M4 and C4 instance types offer more compute processing power, memory, and network performance at lower costs compared to earlier generations. For example, an M4.XL instance offers 13 ECUs (an EC2 Compute Unit is the equivalent of CPU capacity of a 1.0-1.2 GHz 2007 Opteron or 2007 Xeon processor) and 16 GB of memory. In contrast, a first-generation M1.XL instance offers 5 fewer ECUs and 1 GB less in memory while costing 28% more in on-demand pricing. You can view a comprehensive comparison of EC2 instance types at EC2instances.info.
Technology Trends
The move away from local disk storage is also representative of the larger trend in big data processing systems. Spark and Presto enable more interactive, real-time workloads, where there is more of a reliance on in-memory processing and less on local disk. In contrast, MapReduce, Hive, and Pig run on the Hadoop framework, which relies more on local disk is more reliable for batch processing workloads. M4 and C4 instance types are part of this trend.
With the cloud, we can re-think the architecture for running big distributed data processing systems. Hadoop started as the combination of two abstraction layers, HDFS and MapReduce, which logically separated the storage layer from the compute layer. A core characteristic of what made the original Hadoop framework highly scalable was that underlying storage backing HDFS was held within the cluster itself – right inside the compute nodes.
Qubole started with the idea of using S3 as the storage tier (instead of HDFS), hence allowing us to keep compute clusters ephemeral and stateless. Data is read in from S3 at the start of a job and then results and logs are written back to S3 at the conclusion. However, we still make use of local disk storage on the compute nodes for temporary and working storage. Once a job is complete and the cluster shuts down, we have no more use for that ephemeral disk storage. We added support for using EBS volumes, optionally, to augment this working storage buffer.
With M4 and C4 instance types, we attach EBS volumes by default for use as working storage for the cluster (and remove them automatically when the nodes or cluster are terminated). We also support the usual optimizations you’d expect, such as enhanced networking in a secure VPC environment.
Using the M4/C4 instances in Qubole
It’s really easy to get started by using M4 and C4 instance types. While creating a new cluster configuration or modifying an existing one, simply choose the instance type within the node type dropdown menu.
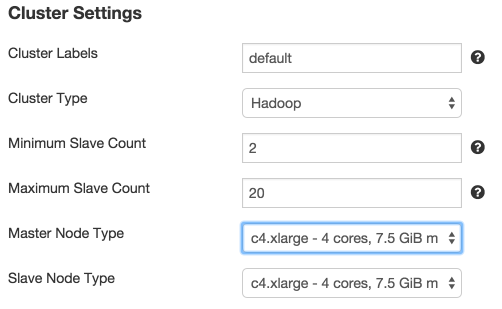
We automatically select one EBS volume of size 100GB if C4/M4 instance types are chosen. We strongly recommend that users do not reset the volume count to zero manually (but they can choose a higher number of volumes or a different volume size if they want). Let us know if you have any feedback on our supported instance types or any questions on M4 and C4 instance types. You can try out Qubole by signing up for our free trial.


