As the demand for leveraging big data to gain insightful analysis has grown, so too have the facilitating technologies. End-users have to adapt to keep pace with the volume of big data as it expands. Today, this requires utilizing the evolution of big data technology. Facebook’s low latency query engine, Presto, presented itself as a good example of an emerging data technology, that deserves attention from anyone looking to really get to grips with their raw data in a meaningful way.
On the MediaMath OPEN analytics team, we deliver a wide range of analytical services to both partners and internal teams. This includes providing statistical data that feed web-based dashboards, and internal ad-hoc requests for data to allow others to make informed strategic decisions. It is often the case that these data requests are time-critical, where we look to supply the results in near real-time. Presto emerged as a potential solution for that use case, to allow us to get data exactly where it needs to be when it needs to be there.
To determine whether Presto could move from a potential solution to a production solution for MediaMath, we subjected it to a number of performance tests, utilizing Qubole’s Presto as a Service. Querying LZOP compressed delimited text files, located on Amazon’s Simple Storage Service (S3). Qubole allows for the ability to auto-scale the number of nodes in a Presto cluster, a feature not available outside of Qubole’s service. We used on-demand nodes for these tests.
All the below tests were performed on a single partition of data, approximately 1.2 billion rows totaling 250GB, in a table in excess of 22TB. These queries represent the average data requests that we face each day.
Query 1: Simple count of rows with a filter on a date partition.
Query 2: Medium complexity, selects 4 dimensions, a count of the rows, and a sum of one column. The ‘where clause’ includes some string comparison ‘(FIELD_A not in (“SOME_STRING”))’. Group by all dimensions selected.
Query 3: High complexity, containing one sub-select. The inner query contains Query 2 but includes an ‘Order By’ clause which sorts on the aggregated column. The outer query selects all resulting columns but limits them to 10,000 rows.
Query 4: Simple query that selects 3 dimensions, but contains multiple math functions, sum, count, and avg.
These four queries were run on a Hive cluster of 50 nodes, and a Presto cluster of just 10 nodes with caching enabled. Currently, caching is a feature that is only available through Qubole’s Presto as a Service offering. Details on caching functionality can be found here.
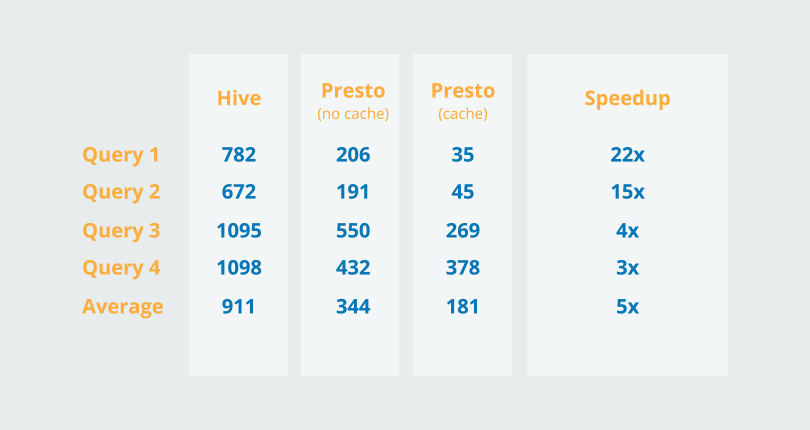
Figure. 1
Figure.1 shows a dramatic improvement in performance (on average a 5x speedup) when using Presto, especially when utilizing the cache. We see the increased drop-off as the queries get more complex, but this is not unexpected and still provides a substantial saving on time. Without using the caching functionality, the results show an average of 2.6x speedup over Hive.
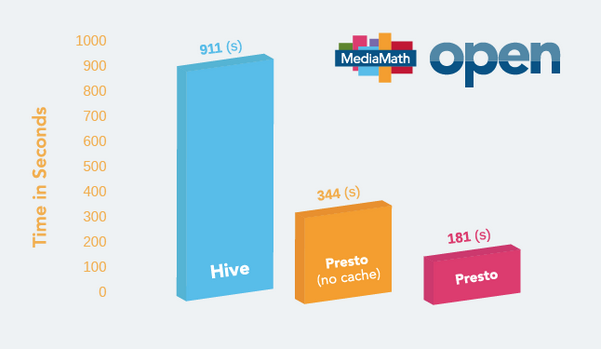
 Figure. 2
Figure. 2
Figure.2 shows the overall trend we see across all four queries and it is easy to see that Presto only takes a fraction of the time to return the same results. With low to medium-complexity queries, Presto completes in well under a minute, with all four queries averaging just 3 minutes.
It is important to keep in mind that these clusters are made up of nodes, that are hired out on a by-hour basis from Amazon at a cost. Using Presto, these four queries could have been executed consecutively almost 5 times over before reaching the end of the first hour. Hive, by comparison, could only run each query once before hours end. This means there was not only a performance increase for each individual query but also a greater return for the cost of the cluster.
Further research has indicated that Presto is most efficient when working on ORC formatted data, where query times can be reduced by up to 10x. Again, this decreases cost over time and increases output, leading to analysts being able to deliver more actionable information at greater speeds.
Presto was announced by Facebook back in July 2013 and later released to the data community as an open-source project. This can only mean good things for its future, as we see more and more additions to its functionality. It has proven already with its performance, that it has a place among the foremost data technologies.
Since running these performance tests, the MediaMath OPEN analytics team has already started to increase Presto’s use across the forms of analyses we provide. We continue to see the fast pace that Presto achieves in the results above, and as our data quickly scales over time, I would not be surprised to see Presto’s query time inversely match that rate of expansion.
In the end, a data analyst has to find the best solution for their analytical puzzles, and really that search should never have a conclusion. If the next step in that exploration is evaluating Presto, then you will be on the right track to transforming a mountain of overwhelming log data into useful actionable knowledge.
Author Bio: Elian Smith is a Senior Analyst for MediaMath.