Introduction
As the Big Data stack has matured, many companies have started using large clusters for running business-critical applications. Workloads in such clusters are often long-running (for hours or even days) and restarting a cluster poses a big problem:
- What happens to jobs that are already running?
- Restarting all these jobs wastes a lot of CPU time. Some jobs may also be latency-sensitive and could miss their deadlines.
- After restarting, a cluster will have to process extra load from the restarted jobs. If the cluster is running at full capacity, this can create even more issues due to excessive contention and load.
- Automated scripts are hard to stop and they may keep generating new jobs (and hence failing) even when the upgrade is in progress.
The classic way of solving this problem is to provide support for in-place upgrades, where nodes are upgraded gradually and the cluster supports a mixture of old and new versions. However, these techniques are complex to engineer and hard to maintain. For end-users, this results in higher costs and uncertainty. Open-source Apache Hadoop started supporting in-place upgrades in Hadoop 2.6 onwards, but it requires manual action on each node and is not as simple as what is possible in Qubole.
Blue-Green Deployments
The cloud presents a far simpler approach in contrast to classic enterprise hardware/software rolling upgrade approaches. This approach is commonly called Blue-Green deployment (see: Blue Green Deployment). It consists of:
- Starting a new tier of hardware with upgraded software
- Testing the new tier and ensuring that it is ready
- Diverting traffic from the old tier to the newly upgraded tier
- Monitoring the new tier to ensure everything is working
- Terminating the old tier when the upgrade is complete
Rejiggering Martin’s picture in the Qubole context would look something like this:
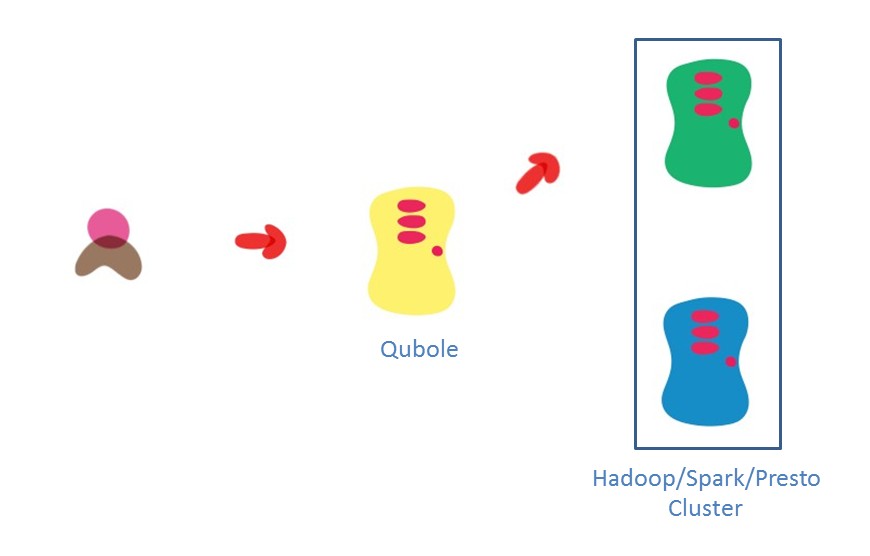
Qubole’s Solution
In Qubole, all jobs (whether they are MapReduce/Spark/Hive/Pig/Presto applications) submitted are directed to specific clusters identified by labels. If no label is specified, the job gets submitted to the cluster with the default label. Labels are unique – and no two clusters can have the same label. Using this labels feature, here’s how one can upgrade the default cluster seamlessly:
- Start a new cluster (by cloning the existing cluster).
- Test the new cluster so that it meets the requirements.
- Divert all the new jobs to the new cluster by re-assigning the default label to the new cluster. The default label will be removed from the old cluster automatically.
- If the new cluster satisfies the requirements, the older cluster can be terminated once the jobs running on them are complete. If for any reason the new cluster shows early signs of a problem, the label can be reassigned back again to the older cluster to let the workflow proceed.
The above process ensures that you don’t have to do anything, not even changing your workflows to point to the new cluster, to divert the jobs to the new cluster. The same recipe applies to any other label.
Auto-Scale Up/Down and Termination
Once you switch the cluster label, the traffic directed to the cluster label goes to the new cluster. At this point, Qubole ensures that:
- the new cluster would automatically scale up as required.
(Note: all Qubole Clusters – Hadoop, Spark, and Presto auto-scale) - as the load on the old cluster drains – it is automatically scaled down
- once the old cluster is idle – it is automatically terminated
- both clusters continue to be monitored and healed.
Thus this procedure leverages Qubole’s auto-scaling and cluster lifecycle management technologies, along with the unprecedented power of large public clouds to provide computing power on demand.
Reassigning Labels from the UI
You can use the Qubole user interface to switch a cluster’s label. In the Control Panel, do a mouse hover on the icon that is to the left of the cluster label (that you want to switch in the Clusters tab of the Control Panel). A tool-tip with the message, click and drag to reassign the label is displayed as illustrated in Figure 1.
that is to the left of the cluster label (that you want to switch in the Clusters tab of the Control Panel). A tool-tip with the message, click and drag to reassign the label is displayed as illustrated in Figure 1.
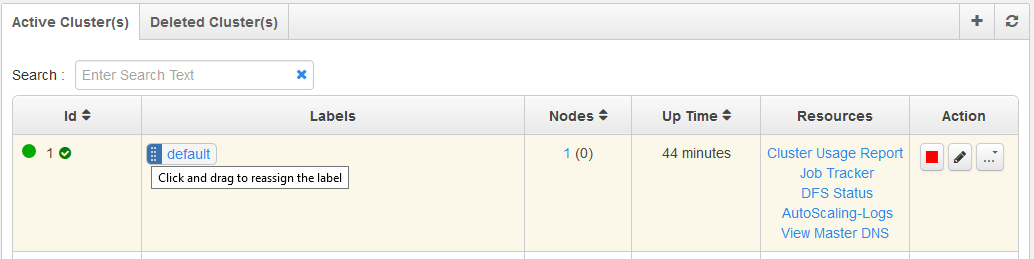
Click the icon buttonand drag to reassign the label to the desired cluster.
Case Studies
Many large customers of Qubole routinely use this capability to achieve low-overhead deployments of Hadoop, Spark, and Presto. We list some example scenarios where this is useful
Case Study 1: Upgrading a large cluster with zero downtime
Imagine that you have one of the leading big data deployments with a hot production cluster with thousands of jobs running on it. Suppose a critical bug fix or performance patch has been identified and needs to be deployed. But restarting the current cluster will terminate all jobs! There are expensive jobs that have been running for hours. Jobs are scheduled from automated scripts and they would start failing as well. Furthermore – the failed jobs will probably retry and add a huge load spike to the cluster after the upgrade.
With Qubole, the rolling deployment upgrade procedure listed above will allow upgrading this cluster with zero downtime, no changes to applications – and no wasted machine hours or load spikes.
Case Study 2: Using clusters with different configurations
Cloud providers expose various parameters that users can tune to achieve goals like lower compute costs, performance, etc. For example, Amazon Web Services (AWS) offers Spot Instances which allow users to bid on unused Amazon EC2 capacity and run those instances for as long as their bid exceeds the Spot Price. Spot Instances can dramatically lower the compute costs by 50-80%. Within the same region, Spot prices can vary across availability zones (mapped to one or more physical data centers).
Spot price spikes in one zone for an instance type being used are not uncommon. A zone can have a high Spot price while other zones might have availability of Spot Instances at much lower prices than on-demand instances.
With Qubole, users can quickly react to such cases by starting a new cluster in the zone having lower Spot pricing and diverting the traffic to the new cluster by reassigning the label. This allows the cluster to operate in the lowest-priced availability zone without any downtime.
Case Study 3: Flexibility in segregating and merging clusters across teams
Multi-tenant clusters lead to better utilization of the underlying hardware resources and lead to lower costs. But, at times, users sharing the resources can have critical requirements for which they might like to have access to dedicated resources. For this case, let us assume there are two teams, Team A and Team B sharing the cluster within the same organization.
A cluster can have multiple labels and in this case, the same cluster can be configured to have two labels corresponding to each team (TeamA and TeamB). Each team submits their workload against the label defined for them.
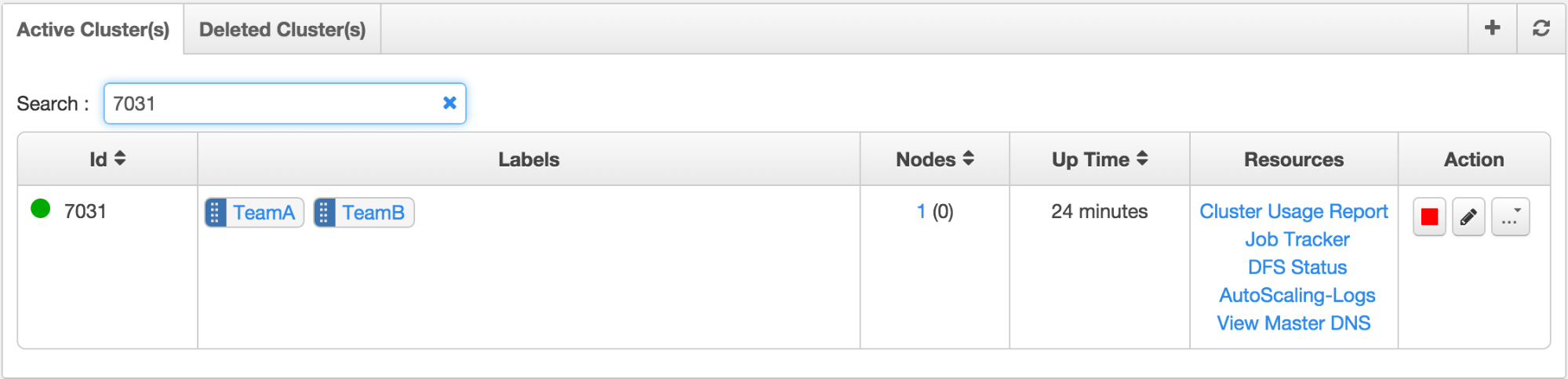
Let us further assume that Team B notices in the middle of their workload that they will need additional resources to meet a deadline for which they need dedicated resources.
To get the results on time, Team B can start a new cluster with the desired configuration, for example, higher-end machines, and reassign the TeamB label to the new cluster. This will divert all new jobs to the dedicated cluster.
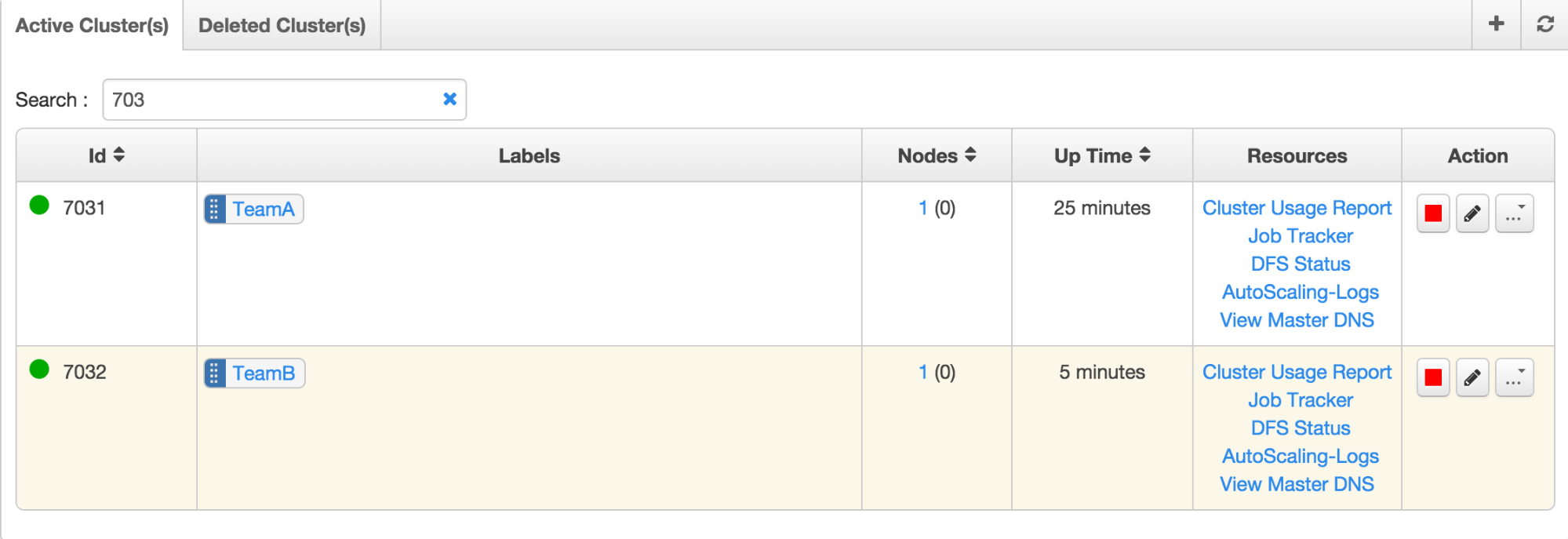
Once the desired results have been achieved, the label (TeamB) can be reassigned to the older cluster to share resources with Team A and the new cluster can be terminated.
Key Points
Cloud platforms offer businesses unprecedented opportunities to take advantage of pooled hardware resources. Problems such as upgrades, splitting, and merging workloads that require expensive and complicated software can now be solved trivially by provisioning new virtual machines dynamically. Qubole capitalizes on such capabilities in the cloud and applies smart software strategies such as the concept of assignable cluster labels (in conjunction with techniques of auto-scaling and cluster lifecycle management) to direct workloads to the appropriate cluster, bringing benefits to enterprise Big Data deployments.



