
Introduction
In the previous blog post, we gave an overview of the data pipeline required to find the trending topics in Wikipedia. In this blog post, we’ll explain how to get the raw data, process it, and get it ready for analysis.
Download Page count files
The first step is to download the page count data feed.
In this demo, all the queries will process data at a granularity of days. Therefore, we’ll partition the table by date. To process data using Qubole, it has to be stored on the AWS S3 service. We have written a Python script to download data to S3 and partition by day. The script is available on GitHub. We ran the script using the Shell Command. Shell command will run the Python script in one of the slaves on the Hadoop cluster. After the command succeeds, one day’s data is available in an S3 directory.
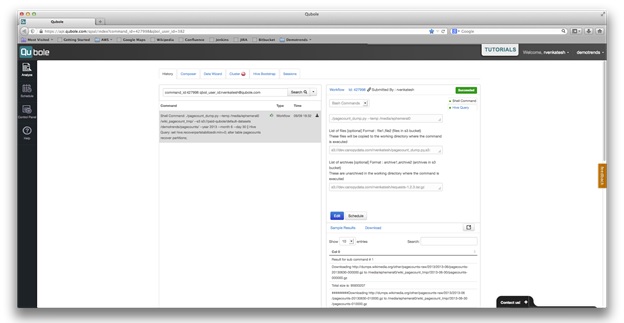
We have made the data available in S3 at s3://paid-qubole/default-datasets/demotrends/pagecounts/.
Create a Hive Table
Apache Hive has a feature – External Tables – which is backed by data NOT managed by Apache Hive. Since Page count will be created and updated by external scripts, we should create an external table with the following command:
CREATE EXTERNAL TABLE pagecounts (`group` STRING, `page_title` STRING, `views` BIGINT, `bytes_sent` BIGINT)
PARTITIONED BY (`date` STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' LOCATION 's3n://paid-qubole/default-datasets/demotrends/pagecounts/';
ALTER TABLE pagecounts recover partitions;
Filter the page counts table
The raw data contains rows from many groups. Since we only care about topics in the ‘en’ group, let’s run an HQL command to filter rows.
set hive.exec.dynamic.partition.mode=nonstrict; set hive.exec.dynamic.partition=true; CREATE TABLE filtered_pagecounts (`group` STRING, `page_title` STRING, `views` BIGINT, `bytes_sent` BIGINT) PARTITIONED BY (`date` STRING);
FROM pagecounts pvs INSERT OVERWRITE TABLE filtered_pagecounts PARTITION(`date`) SELECT pvs.`group`, pvs.page_title, pvs.views, pvs.bytes_sent, pvs.`date` where
not pvs.page_title RLIKE '(MEDIA|SPECIAL||Talk|User|User_talk|Project|Project_talk|File|File_talk|MediaWiki|MediaWiki_talk|Template|Template_talk|Help|Help_talk|Category|Category_talk|Portal|Wikipedia|Wikipedia_talk)\:(.*)' and
pvs.`group` = 'en' and not pvs.page_title RLIKE '([a-z])(.*)' and not pvs.page_title RLIKE '(.*).(jpg|gif|png|JPG|GIF|PNG|txt|ico)' and
pvs.page_title <> '404_error/' and pvs.page_title <> 'Main_Page' and pvs.page_title <> 'Hypertext_Transfer_Protocol' and pvs.page_title <> 'Favicon.ico' and pvs.page_title <> 'Search';
Above Hive command creates another table ‘filtered_pagecounts’ which is also partitioned by date. The command will process many partitions. We have to specify ‘nonstrict’ partition mode and turn on Dynamic Partitioning because we are not inserting it into a specific partition. Click here for more details on Dynamic Partitions.
The rest of the command filters out rows that match a set of criteria.
Create Synonym Lookup Table
Wikimedia provides Page and Redirect tables as MySQL dumps. These tables are very big. The page table has 10+ million rows and the redirects table has 6+ million rows and it took us 11+ hours to import the MySQL dumps into a DB. Once the data is in MySQL DB, the transformation required on these tables is simple and can be done by writing some join queries. But the size of tables is huge making it a very time-consuming task to do these transforms in MySQL.
Instead of using MySQL, we can transform these tables in Apache Hive.
Import Data from MySql tables to Hive
Qubole provides connectors to pull data from many RDBMS and no SQL dbs into Hive. Using Qubole we can pull all the data in pages and redirect the table into Qubole. To import data from an external data source you first need to create a DbTap by giving us the basic Db credentials. This DbTap can be used to create a Data Import Command. The command accepts arguments for dbtap, parallelism, db query, hive table, etc to load data into the Page and Redirect table in the hive. An example of the command to download the page table is shown below.
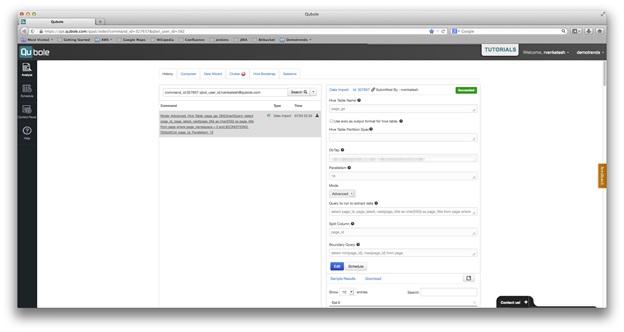
These commands run for about 2-5 minutes (the exact time depends on how much parallelism is used) each and import 10million+ rows from MySQL into the hive.
Page and Redirect Tables as Flat Files
Qubole Import Command by default generates flat files in s3 as output. We have provided the output data (for page and redirect hive tables) of db import commands described in the last step in a “paid-qubole” s3 bucket. You can directly create the page and redirect hive tables on top of this data:
CREATE EXTERNAL TABLE page (`page_id` BIGINT, `page_latest` BIGINT, `page_title` STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\001' LOCATION 's3n://paid-qubole/default-datasets/demotrends/page/';
CREATE EXTERNAL TABLE redirect (`rd_from` BIGINT, `page_title` STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\001' LOCATION 's3n://paid-qubole/default-datasets/demotrends/redirect/';
This will save you 11+ hours of time for uploading MySQL dumps to a database.
Transforming data in Hive using HQL
Once the data is in hive tables(page and redirect), we use a 3 step process to create the synonym lookup table.
- Generate a table (page_lookup_nonredirect) for canonical pages i.e. pages that are not redirected to another page:
Redirect Id | Redirect Title | True Title | True Id |
| 12345 | India | India | 12345 |
CREATE TABLE page_lookup_nonredirect (redirect_id bigint, `redirect_title` STRING, `true_title` STRING, `page_id` BIGINT, page_version BIGINT); INSERT OVERWRITE TABLE page_lookup_nonredirect SELECT page.page_id as redircet_id, page.page_title as redirect_title, page.page_id, page.page_title true_title, page.page_latest FROM page LEFT OUTER JOIN redirect ON page.page_id = redirect.rd_from WHERE redirect.rd_from IS NULL;
- Generate a table (page_lookup_redirect) for titles that are redirected to a canonical title:
Redirect Id | Redirect Title | True Title | True Id |
| 67567 | Bhart | India | 12345 |
| 56765 | Al_HIND | India | 12345 |
CREATE TABLE page_lookup_redirect (redirect_id bigint, `redirect_title` STRING, `true_title` STRING, `page_id` BIGINT, page_version BIGINT);
insert overwrite table page_lookup_redirect
select original_page.page_id redirect_id, original_page.page_title redirect_title, final_page.page_id, final_page.page_title as true_title, final_page.page_latest from page final_page join redirect on (redirect.page_title = final_page.page_title) join page original_page on (redirect.rd_from = original_page.page_id);
- Finally, union page_lookup_nonredirect and page_lookup_redirect
CREATE TABLE page_lookup (redirect_id bigint, `redirect_title` STRING, `true_title` STRING, `page_id` BIGINT, page_version BIGINT); INSERT OVERWRITE TABLE page_lookup select redirect_id, redirect_title, page_id, true_title, page_latest from ( select redirect_id, redirect_title, true_title, page_id, page_latest FROM page_lookup_nonredirect UNION ALL select redirect_id, redirect_title, true_title, page_id, page_latest FROM page_lookup_redirect ) u;
Conclusions
- Qubole makes it easy to import data into Hive from Mysql, postgres, Vertica, redshift, and mongo db.
- Hive supports many complex SQL constructs like join, left join, outer joins, and union.
- Because hive runs everything in parallel all these queries complete very fast.
In the next section, we’ll use Apache Hive to process the data and score all the topics.


